
[더팩트ㅣ이성락 기자] LG그룹이 전 세계 인공지능(AI) 연구자를 대상으로 개최하는 'LG 글로벌 AI 챌린지'에서 이미지를 이해하고 설명하는 인공지능(AI)을 소개한다.
LG AI연구원은 다음 달 1일부터 4월 말까지 온라인으로 'LG 글로벌 AI 챌린지'를 연다고 31일 밝혔다.
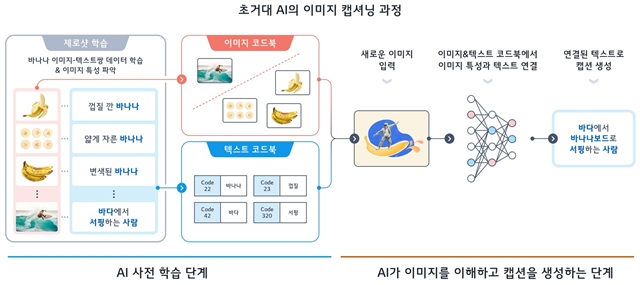
이번 대회는 '제로샷 이미지 캡셔닝'을 주제로 열린다. AI가 처음 본 이미지를 얼마나 정확하게 이해하고 설명하는지 평가하는 방식이다.
'제로샷 이미지 캡셔닝'은 AI가 마치 사람의 시각 인지 능력처럼 처음 본 사물, 동물, 풍경 등이 포함된 이미지를 봤을 때나 일러스트레이션, 그래픽 등 표현 방식이 다른 이미지를 봤을 때 기존 학습한 데이터를 기반으로 스스로 이해하고 유추한 결과를 텍스트로 설명할 수 있는 기술이다.
토끼를 한 번도 본 적이 없는 사람이 토끼 여러 마리와 고양이 한 마리가 함께 있는 것을 봤을 때 동물들의 생김새·특성의 공통점과 차이점을 학습하고 '토끼도 털은 있지만 고양이와는 다르게 귀가 길고, 뒷다리가 발달했다'고 설명할 수 있는 것처럼 '제로샷 이미지 캡셔닝'의 작동 구조도 이와 유사하다.
'제로샷 이미지 캡셔닝' 기술이 점차 고도화되면 이미지 인식 AI 기술의 정확성과 공정성이 향상되고 결국 사람들의 실생활에 직접적으로 도움을 줄 수 있는 기술 개발로 이어질 수 있다.
예를 들어 AI가 자동으로 캡션과 키워드를 생성해 검색의 편의성과 정확도를 향상시킬 수 있다. 또 의학 전문 데이터를 추가 학습할 경우 의학 영상을 분석하는 '의학 전문가 AI'로 활약할 수 있다.
'제로샷 이미지 캡셔닝'은 인간의 학습 구조를 모방한 초거대 AI가 등장하며 기술 연구가 활발해지고 있으며, 최근 화두가 되고 있는 텍스트를 이미지로 변환하는 '생성형 AI 모델'의 성능은 물론 이미지 검색의 정확도를 높이는 데도 활용되고 있다.
LG는 사람의 시각 인지 능력에 가까이 다가서는 '제로샷 이미지 캡셔닝'이 이미지를 텍스트로 표현하고, 텍스트를 이미지로 시각화할 수 있는 초거대 멀티모달 AI인 '엑사원'의 기술 개발 생태계에 크게 기여할 것으로 기대하고 있다.
LG AI연구원은 공동연구센터를 설립해 초거대 멀티모달 AI인 '엑사원'을 연구 중인 '서울대학교 AI대학원', 이미지 캡셔닝 AI의 상용화 서비스를 공동으로 준비 중인 '셔터스톡'과 함께 이번 경진 대회를 열기로 했다.
LG AI연구원은 오는 6월 캐나다 밴쿠버에서 열리는 컴퓨터 비전 분야 세계 최고 권위 학회인 'CVPR 2023’에서 '제로샷 이미지 캡셔닝 평가의 새로운 개척자들'을 주제로 워크숍도 열 예정이다.
김승환 LG AI연구원 비전랩장은 "세계적인 학회에서 영상 이해의 핵심 기술이자 기반 기술인 이미지 캡셔닝을 주제로 대회를 개최한 것은 LG가 컴퓨터 비전 분야의 글로벌 입지를 보여준 계기"라며 "이번 대회를 통해 전 세계 AI 연구자들과 함께 연구의 의의와 필요성, 그리고 확장 가능성에 관해 함께 논의하는 장을 만들고자 한다"고 말했다.
rocky@tf.co.kr
- 발로 뛰는 <더팩트>는 24시간 여러분의 제보를 기다립니다.
- · 카카오톡: '더팩트제보' 검색
- · 이메일: jebo@tf.co.kr
- · 뉴스 홈페이지: https://talk.tf.co.kr/bbs/report/write
- · 네이버 메인 더팩트 구독하고 [특종보자→]
- · 그곳이 알고싶냐? [영상보기→]
